

今日の授業では、SQL(Structured Query Language)の基本操作について学びます。Google BigQueryを使って、シェークスピアのサンプルデータベースにアクセスし、データの検索やカウントなど、実際にSQLを作成して試してみましょう。この授業を通じて、データベースの扱い方や情報の整理・抽出方法について理解を深めます。
黒板

授業
テーブルの構造とは?
さて、SQLを学ぶ前に、リレーショナルデータベースの基本的な概念、テーブルの構造について確認しよう。
テーブルって何ですか?
テーブルはデータベースの中でデータを保存するためのものだよ。テーブルは行と列から成り立っていて、行はレコード、列はカラムと呼ばれる。そして、各レコードの各カラムのデータをフィールドと呼ぶんだ。
なるほど、Excelのシートみたいな感じですか?
そうだね、Excelのシートと似ているけど、データベースのテーブルはもっと大量のデータを効率的に管理するためのものだよ。
了解です。
SQLを使ってみよう!
前回SQL言語について簡単に説明したけれども。覚えているかな?
リレーショナルデータベースでデータを操作するためのプログラミング言語でしたよね。
さすが!今回はその実践編だ。Google BigQueryを使って、実際にデータベースにアクセスしてみるんだ。
BigQueryって何ですか?
Google BigQueryは、Googleが提供する大規模データ解析サービスだよ。SQLを使ってデータを簡単に操作できるんだ。
なるほど、それって無料で使えるんですか?
一部の機能は無料で使えるよ。ただし、大量のデータを扱う場合や高度な分析をする場合は、料金が発生することもあるから注意が必要だね。今回は無料の範囲で利用するから安心してね(アクセス方法は文末を参照願います)。
了解です。
BigQuery の一般公開データセットへログイン
では、Googleのサイトから一般公開のデータセット(https://cloud.google.com/bigquery/public-data?hl=ja)にアクセスしてみよう。
「GoogleSQL クエリを使用して分析できる一般公開データセットが用意されている」と書いてあるね。
そうだね。今回はこの中から、サンプルテーブルとして公開されている、シェークスピア作品の単語の出現回数が記録されているデータベース(shakespeare)をクリックしてみよう。

シェークスピア?なんで大昔の作家のデータベースがあるんですか?
実は、シェークスピアの作品はテキストデータとしてよく使われるんだ。データの検索や分析に適しているかなんだ。
なんだか面白そうですね。
なおや君は、どんな単語が一番使われていると思う?
そうだな。シェークスピアというと、イギリスの王様を描いた作品が多かったと思うので、「king」じゃないかな?
おっ!なんだか詳しいね。先生は「love」だと思うな、ロミオとジュリエットでは、何度も愛を囁いていたからね。
先生ってそんなにロマンチストなんでしたけっけ?うーん、待ちきれない。早速SQL実行ですね。
スキーマの確認
はやる気持ちはわかるけれど、まずはスキーマを見てみよう。
スキーマ?なんですかそれは?
データベーススキーマとは、データがデータベース内でどのように構造化または組織化されているかを記述したものだよ。

そう言われても、なんのことやら・・・
まあ、実際に見てみよう。画面上の「スキーマ」をクリックしてみると、word、word_count、c、corpus_dateの4種類のフィールド名が定義されていることがわかるよね。
そうですね。説明が英語なので、ちんぷんかんぷんですが・・・
wordはシェークスピアの作品に出現する単語、word_countは、この単語が出現する回数、corpusは作品名、corpus_dateは作品の公開年だ。
なるほど、どんな単語がどの作品に何回登場したか、記録されているということでうすね。ところで、種類にあるSTRINGとかINTEGERというのはなんですか?
これはフィールドの種類が、文字列ならSTRING、整数の数字ならINTEGERで定義しているんだ
なるほど。Pythonでも、最初に変数の型を定義しましたが、データベースでは、スキーマで定義するんですね。
データプレビュー
実際のデータの全体像はプレビューで確認できるよ。
この「プレビュー」ボタンを押すんですね。お、何か出てきましたね。
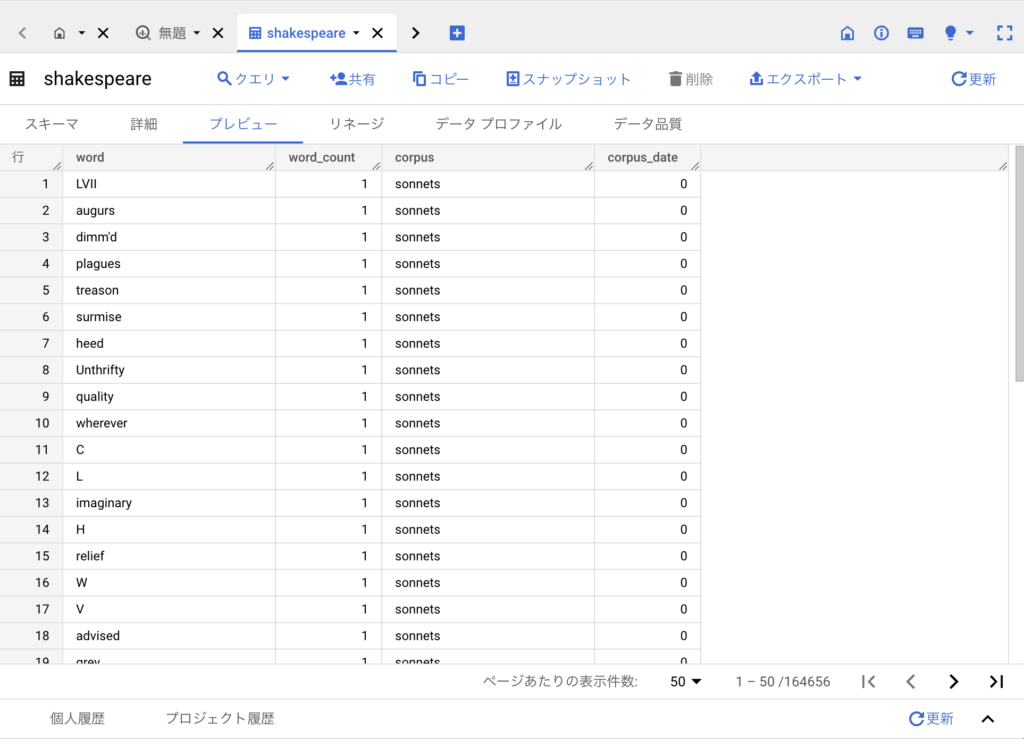
そうだね、先ほどのスキーマに定義されたテーブルが表示されたよね。”word”の欄に単語が並んでいるよね。このテーブルはword_countが小さい値から順に並べられているようだね。
あまり見慣れない単語が並んでいますね。右下の「ページを進む」を押すと、先に進めますね。一番最後の行は164,656行ですね。それにしても、すごい行数ですね。
そうだね。Excelでは10万行を超えるデータを扱うとすぐに重たくなってしまうけれど、データベースではこれくらいは問題ないよ。
とにかく、これだけの文章を作ったのだから、シェークスピアは偉大ですね。
SELECT、FROM
さて、基本的なSQLの操作に移ろう。最初に特定の列を取り出してみよう。
前回習った「射影」ですね。実際には、どうやるんですか?
次のように、SELECT文で列を指定すれば良いんだ。
SELECT 列名 FROM テーブル名;
FROMというのはなんですか?
どのテーブル取得するかを示しているんだ。
さっきからテーブルって言う言葉が出ていますが、データベースとは違うんですか?
いい質問だね。データベースは複数のテーブルを持つことができる大きな容器のようなものだよ。各テーブルは特定のデータを格納していて、それぞれが列と行で構成されている。
なるほど、テーブルはデータベース内の一部で、特定のデータを管理しているわけですね。
今回利用するのは、bigquery-public-data.samples というデータベースの、shakespeareというテーブルなんだ。それを繋げてbigquery-public-data.samples.shakespeareとしたものを完全修飾名と呼び、この名前をFROMの後に記載するよ。
-- シェイクスピアの作品から単語とその出現回数を取得するSQLクエリ SELECT word, -- 単語を選択 word_count -- 単語の出現回数を選択 FROM `bigquery-public-data.samples.shakespeare`; -- データソース
急に行数が多くなりましたけれど・・・
まず、SQLの命令文は、改行や字下げ、スペースに関しては自由に書くことができるんだ。つまり、見やすさや理解しやすさのために、自分の好みやチームのルールに合わせて、適切に改行や字下げを入れることができるよ。
なるほど。ところで、これをどこに入力すれば良いのですか?
BigQueryの画面で、+マークのボタンが「クエリの追加」のボタンなので、これを押してみて。クエリとはデータベースに対する命令文のことだよ。
「無題2」というタブができましたね。ここに今のSQL文を入力するんですね。
その通り。二重ハイフン (—)の後の文字は、コメントだから省略しても大丈夫だよ。
入力しました!実行します!

どうだった?
おっ、画面の下に「クエリ結果」が表示されましたね。行数は同じで、wordとword_countだけが選択されています。一瞬でしたね。
うまく行ったようだね。この処理はGoogle Cloudという性能の良いサーバーを使っているので、10万行程度の処理ならほとんど待ち時間なく処理できるんだ。
ORDER BY
列が選択されたのは良いのですが、目的は単語の発生頻度の順番を知りたいので、表示順番を変えられませんか?
そうだよね。表示順を変えるにはORDER BY 句を使うよ
SELECT 列名 FROM テーブル名 ORDER BY 列名 [ASC もしくは DESC];
最後のASCもしくはDESCというのは何?
ASCはascending orderの略で、昇順つまりは小さい順という意味だよ。一方、DESCはdescending orderの略で、降順つまり大きい順という意味だ。
ふむふむ。では今回はword_countの大きい順に表示させたいので、「ORDER BY word_count DESC」という行を追加すれば良さそうですね。
-- シェイクスピアの作品から単語とその出現回数を取得し、出現回数で降順にソートするSQLクエリ SELECT word, -- 単語を選択 word_count -- 単語の出現回数を選択 FROM `bigquery-public-data.samples.shakespeare` -- データソース ORDER BY word_count DESC; -- 出現回数の降順でソート
さすが、完璧だね。実行してみて。
よし、実行。
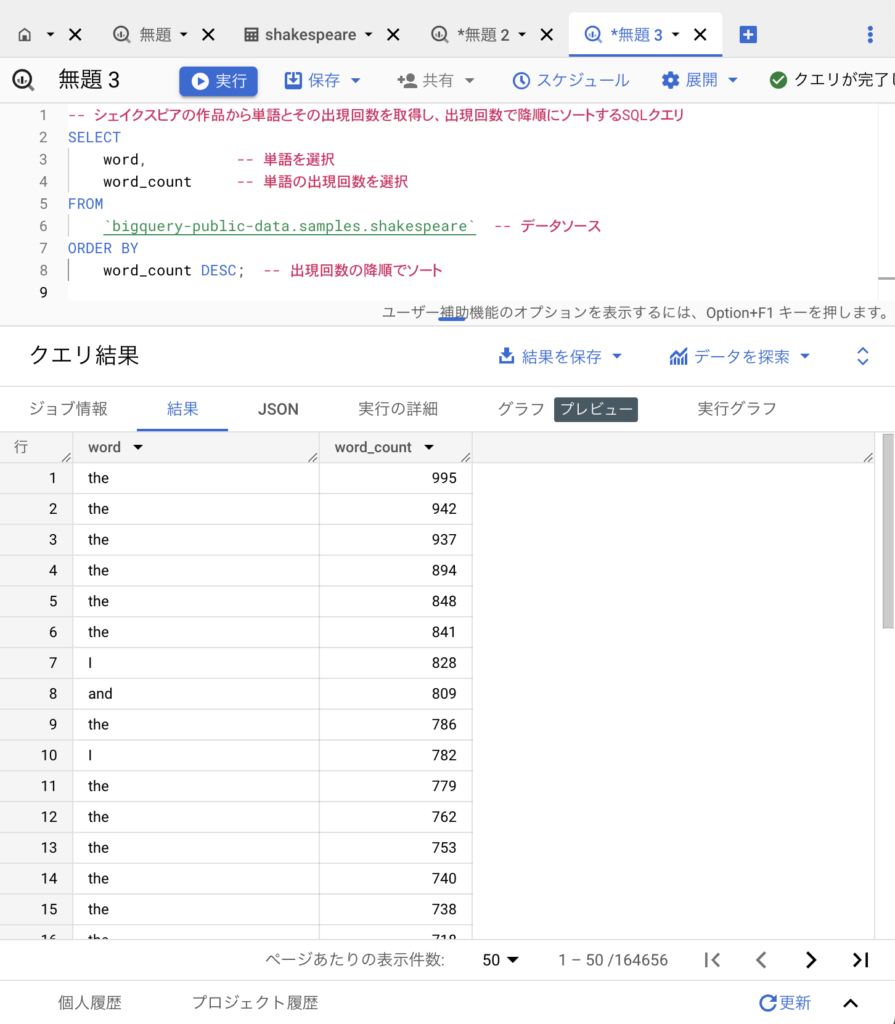
どうだった?
大きい順になりましたね。”the”が一番か!でも、同じ単語が何個も並んでいて変ですね。
そうだね。これは列を抜き出しただけだから、作品別のカウントになっているんだ。
うーん、単語毎の合計を表示してほしいですね。
SUM関数
合計にするにはSUM関数を使うんだ。構文は以下の通り、SELECT文の中で指定すれば良いんだ。
SELECT SUM(カラム名) FROM テーブル名;
関数があるなんて、プログラミング言語に似ていますね。
そうだね。じゃあ、今回のケースで変更するとどうなるかな?
SELECT文を「SELECT word ,SUM(word_count)」に書き換えれば良さそうですね。
さすが、飲み込みが早いね!
よし実行!あれ?クエリ結果のところにエラーが表示されてしまいました。先生間違ったことを教えましたか?
あらら、少し急ぎすたね。今回はwordごとに複数の作品を合計して表示させたいんだよね。
すごくややこしい言い方ですけど、その通りです。
GROUP BY句を使用することで、同じ値同士のデータをグループ化できるんだ。
ふむふむ。今回はwordごとに表示したいから、「GROUP BY word」と入れればよいのかな?
-- シェイクスピアの作品から各単語の出現回数を合計して取得するSQLクエリ SELECT word, -- 単語を選択 SUM(word_count) -- 単語の出現回数を合計 FROM `bigquery-public-data.samples.shakespeare` -- データソース GROUP BY word; -- 単語でグループ化
良いね。今度は実行して大丈夫そうだね。
じゃあ実行します。
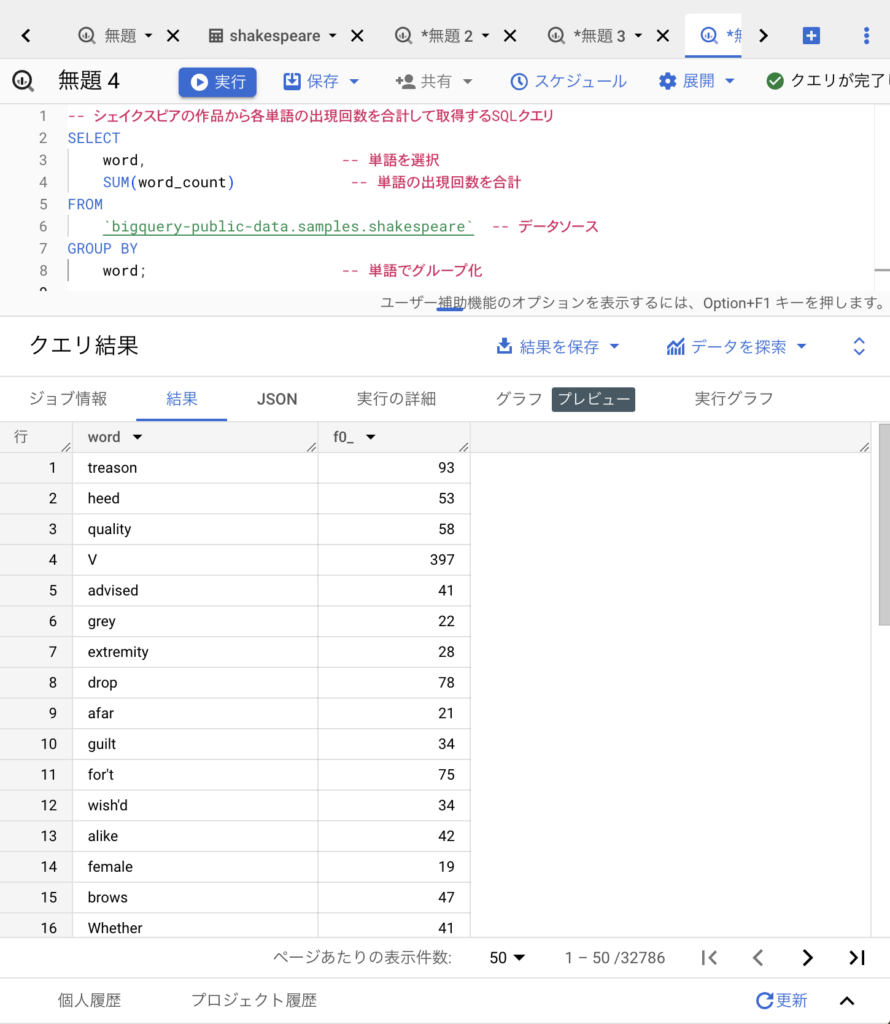
どうたった?
それらしい結果が出ました。合計された値は「f0_」という謎の名前になってますが、ちゃんと合計されている感じです。
おっ、やったね
AS
うーん、でもこれだと、順番がめちゃめちゃですね。word_countの合計が大きい順に並べたいんですけれども、さっきのORDER BYは使えないのですか?
合計した値を順番に並べるには、合計した数に別の名前をつける必要があるんだ。
さっき「f0_」という名前になっていた謎の列に、名前をつけて、それでソートするということですね。
鋭いね。 別名を付けたい場合、AS句というものを使うと、列に別名が付けられるんだ。以下のような形になるね。
SELECT カラム名 AS 別名 FROM テーブル名;
なんだか、SELECTの後ろがにぎやかになってきましたね。
そうだね。word_countの合計にtotal_word_countという別名をつけてみよう。
「SELECT word, SUM(word_count) AS total_word_count」でいいですか。
さすが!後はtotal_word_countの順番でソートすれば良いね、
「ORDER BY total_word_count DESC」ですね。
その通り。完成形は次のようになるよ。
-- シェイクスピアの作品から各単語の出現回数を合計し、出現回数で降順にソートするSQLクエリ SELECT word, -- 単語を選択 SUM(word_count) AS total_word_count -- 単語の出現回数を合計 FROM `bigquery-public-data.samples.shakespeare` -- データソース GROUP BY word -- 単語でグループ化 ORDER BY total_word_count DESC; -- 出現回数の降順でソート
さあ実行。

どうだった?
“the”が25568回で1位、次は”I”、その次は”and”・・・。冠詞や接続詞、代名詞ばかりですね。考えてみれば当たり前か・・。
そうかも知れないね。実際に実行して仮説を検証するということには意味があるよね。なおや君と先生が予想した”king”や”love”はあるかな?
えーと、次ページボタンを押すと、あった。先生が予想したloveは2,135回で60位、俺が予想したkingは1,191回で108位。うーん、先生の勝ちか。。
ははは、一応年長者の面目が保てたかな。
WHERE
うーん。でもこうして、次ページボタンを使って探していたんじゃあ、見つかるかどうかわからないですね。
そうだね、そんなときにはWHERE句を使って条件式を指定することにより、その条件にマッチしたレコードだけを選択することができるんだ。
SELECT 列名 FROM テーブル名 WHERE 条件式;
検索するイメージですか?
そのとおりだね。「WHERE word = ‘king’」という行を追加すると、kingに合致した行だけが表示される。
-- シェイクスピアの作品から「king」という単語の出現回数を集計するSQLクエリ SELECT word, -- 単語を選択 SUM(word_count) AS total_word_count -- 単語の出現回数を合計 FROM `bigquery-public-data.samples.shakespeare` -- データソース WHERE word = 'king' -- 単語が「king」であるレコードのみをフィルタ GROUP BY word -- 単語でグループ化 ORDER BY total_word_count DESC; -- 出現回数の降順でソート
やってみます。
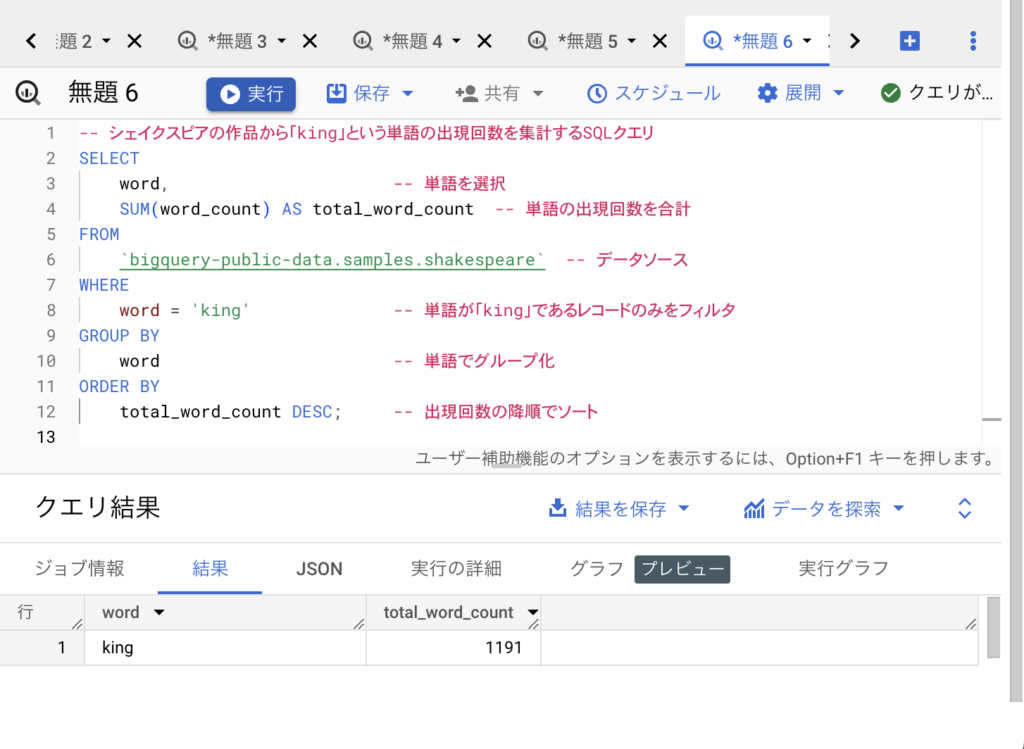
どうだった?
本当だ!先ほどページを進めて見たking 1,191回という結果だけが表示されましたね。
やったね。これで完璧かな?
WHERE 複数条件
うーん、まだ納得いかないな。王様の名前を表す時には、KINGと大文字を使うんじゃないかな?kingとKINGの両方で検索したら、結果が変わるんじゃないかな?
なるほど。大文字と小文字は区別されているから、その可能性はあるね。WHERE句ではandやor等の演算子も使えるよ。「WHERE word = ‘KING’ or word =’king’」に変更して実行してみよう。
-- シェイクスピアの作品から「KING」または「king」という単語の出現回数を集計するSQLクエリ SELECT word, -- 単語を選択 SUM(word_count) AS total_word_count -- 単語の出現回数を合計 FROM `bigquery-public-data.samples.shakespeare` -- データソース WHERE word = 'KING' OR -- 単語が「KING」であるレコードをフィルタ word = 'king' -- または単語が「king」であるレコードをフィルタ GROUP BY word -- 単語でグループ化 ORDER BY total_word_count DESC; -- 出現回数の降順でソート
さあ実行。
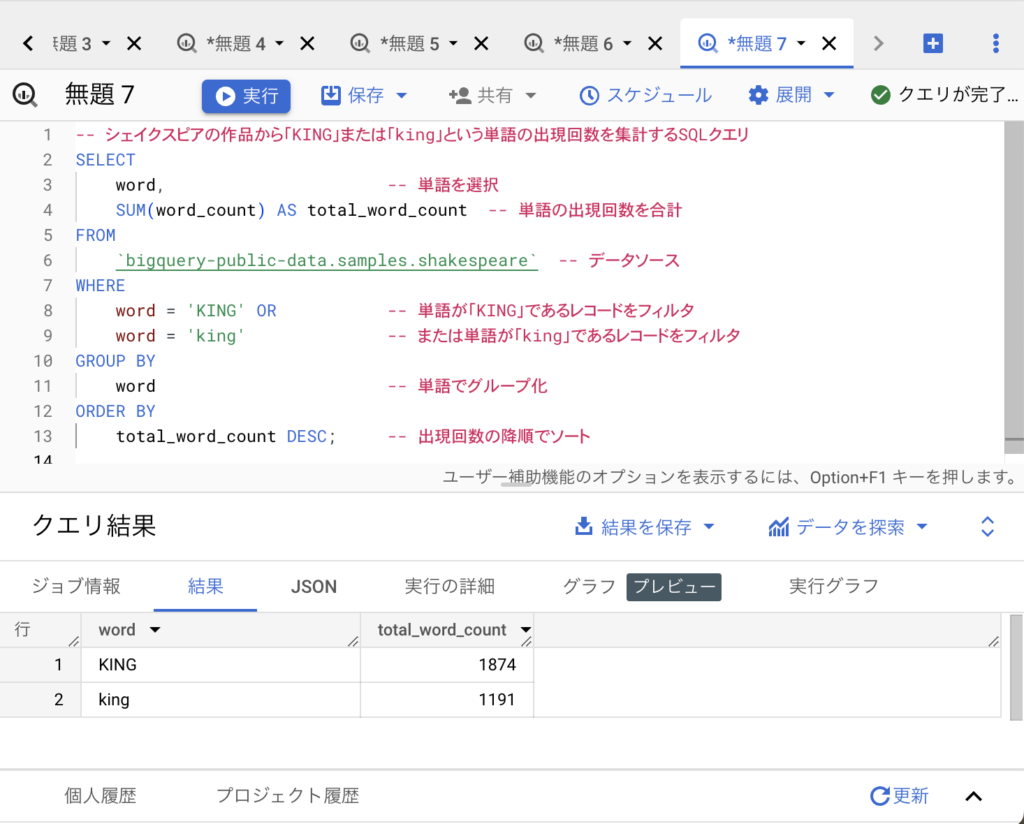
むむむ。
やっぱりだ、大文字のKINGが1874回、小文字のkingが1191回。合計すると3,065回だよ。
おっと。じゃあ、大文字のLOVEを含めて検索してみよう・・。残念、大文字は0回だった。
じゃあ、KING+kingが3,065回、LOVE+loveが2,135回で、俺の勝ち!
残念。なおや君の結果に対する、鋭い洞察に負けました。今回の演習はどうだった?
めっちゃ楽しかったです。こうやってSQLを使ってデータを分析することで、すごい発見があるかもって思ってきました。
それは良かった。他にもBigQueryには一般公開されているデータセットも多くあるし、その他のデータを読み込んで分析することもできるので、ぜひチャレンジしてみてね。
はい、早速やってみます!
Google BigQueryの利用方法
Google BigQueryは、Googleが提供する大規模データ解析サービスです。Webブラウザ上でコードを直接実行し、結果を即座に確認することが可能です。
BigQuery サンドボックスは、制限付きの BigQuery の機能を無料で試すことができるので、SQLの学習にも利用できます。
以下にセットアップの方法を記しますので、ぜひ各自でセットアップし、今回の授業のSQLを実際に試してみてください。
詳しくはgoogleのWebサイト(https://cloud.google.com/bigquery/docs/sandbox?hl=ja)を参照願います。
なお、以下の手順は既にGoogleアカウントを持っていることを前提としています。Googleアカウントがない場合には、Googleアカウント作成ページにアクセスしてアカウントを作成してください。
ログイン方法
1.BigQueryサンドボックスにアクセス
ブラウザより、以下のURLにアクセスします
https://console.cloud.google.com/bigquery
2.googleアカウントでログインする
3.Googl Cloudようこそ画面
・国の選択
・利用規約にチェック
・「同意して実行」をクリック
4.SQLワークスペース画面
「プロジェクトを作成」をクリック
5.新しいプロジェクト画面
・プロジェクト名が「My Project XXXXX」が表示されますので、好きな名前に変更するか、この値をメモしてください。
・作成をクリック
6.「Cloud コンソールの BigQuery へようこそ」という画面が表示されたら完了です
「完了」をクリックしてください
左上に「サンドボックス」という表示があることを確認してください。ここんに「サンドボックス」が表示されている状態は、無料で試している状態ですので、一切費用はかかりません。
ここまで行けば、一般公開データセットにアクセスできるようになります。以下のサイトから、興味のあるデータベースにアクセスしてみてください。
https://cloud.google.com/bigquery/public-data?hl=ja
まとめ
- リレーショナルデータベースの基本概念
データベースは情報を保存、管理するためのシステムで、テーブルという形でデータが格納される。 - テーブルの構造
テーブルは行と列から成り立ち、行はレコード、列はカラムと呼ばれる。各レコードの各カラムのデータはフィールドと呼ぶ。 - データの取得
特定の列のデータを取得するには、SELECT 列名 FROM テーブル名;というSQL文を使用する。 - データのソート
データを特定の列の値に基づいてソートするには、ORDER BY句を使用する。 - 条件付きのデータ取得
特定の条件を満たすデータのみを取得するには、WHERE句を使用して条件式を指定する。
名言解説
We thought that these people shouldn’t have to turn themselves into computer experts or programmers in order to ask questions. Donald D. Chamberlin
ドナルド・D・チェンバリン、データベース管理システムの分野での先駆者として知られ、特にSQL(Structured Query Language)の共同開発者として知られています。
この言葉は、ドナルド・D・チェンバリンが、彼の同僚レイモンド・F・ボイスがSQLを開発した背景と目的をインタビューで語ったものです。彼らの目的は、エンジニアや経済学者などの専門家が、プログラマーやコンピュータ専門家になることなくデータベースにアクセスできるようにすることでした。SQLは、これらの専門家が自分の専門分野に関する情報を簡単に取得できるように設計されました。
この名言から学べることは、技術やツールは常に人々の生活を簡単にするために開発されるということです。SQLのような技術は、専門家だけでなく、私たち一般人の生活も豊かにするために存在します。技術の背後には、常に人々のニーズや問題解決のための思いが込められています。皆さんも、技術を学ぶ際には、それがどのように人々の生活を向上させるのか、その背景や目的を考えながら学んでみてください。
問題
「クイズをスタート」のボタンをクリックすると、5問出題します。さあチャレンジ!
編集者ひとこと
SQL実践編いかがでしたでしょうか?実際に触ってみて試してみてもらいたかったので、WebでSQLを学べるサービスを探しましたが、どれが良いのかよく分からず、お試しにも、超本格的なビックデータ解析にも使えるGoogleのサービスを利用することにしました。自分でデータをインーとして利用することもできるので、お試し範囲で思いっきり使ってみてください。習うより慣れろですね。
他にどんなSQLがあるのか、チャットボックスで聞いて見てくださいね。例えば「代表的なSQL構文を20個あげてください」というように聞くとリストアップしてくれます。さらに、「XX文の利用例を示して」と聞けば、具定例をあげてくれます。ぜひ、チャット機能を活用して、実践してみてください。
<RANKING>![]()
高校教育ランキング

