

本日の授業では、テキストマイニングについて学びます。自由なフォーマットで記述された文章データから有用な情報を抽出する技術です。形態素解析を使い、言語の最小単位でデータを分割し、専用ツールで効率的に分析します。
黒板

授業
テキストマイニングとは?
さて、なおや君、テキストマイニングって聞いたことあるかな?
うーん。マイニングって採掘とかそういう意味でしょ。だから、文章を発掘するというような意味かな?
いいね。もっと具体的に言うと、テキストを言葉の最小単位に分けて、それを分析する技術なんだよ。
どんな時に使うんですか?
例えば、SNSのトレンドワードがランキングで表示されているけれど、あればテキストマイニングの例だよ。
形態素解析について
SNSのトレンドワードってよく見るね。でも文章から言葉を取り出そうとしたときに、言葉の意味が分かっていないとできないよね。難しそう。
いい質問だね。そのための解析が形態素解析というんだ。
形態素解析?なんですかそれ?
形態素とは、言語学の用語で、意味をもつ表現要素の最小単位だよ。
ふーん、じゃあ形態素を解析するということは、文章を品詞単位で分解して分析するということ?
そのとおり。たとえば「今日はよい天気です。」という文章を「今日(名詞)」「は(助詞)」「よい(形容詞)」「天気(名詞)」「です(助動詞)」という具合に区切るんだ。
なるほど、それで文章の意味を分析できるんですね。
そうなんだ。そして、この区切られた単語を使って、単語出現頻度、つまりどの単語がよく出てくるかを分析するんだよ。
実践!テキストマイニング
そう、じゃあ実際にやってみようか。まず、形態素解析でテキストを単語に分解するよ。
やってみたいです!どうやるんですか?
今回もpythonとGoogle Colaboratory を使って実行てみよう。Google Colaboratoryについては、以前(45.データの整形と修正)詳しく解説しているので、初めての人はそちらから確認してね。
Python ってなんでもできるんですね。
そうだよ。Pythonはデータ分析のためのライブラリが充実しているんだ。ここでは、janomeというオープンソースの形態素解析エンジンを使うよ。
なんだか楽しそう。何のテキストを使って分析するんですか?
今回は、この情報寺子屋のブログを読み込んで、出現する単語を集計してみよう。
結果の可視化
# 必要なライブラリをインストール
!pip install janome matplotlib wordcloud
!apt-get -y install fonts-noto-cjk
# 必要なライブラリをインポート
from janome.tokenizer import Tokenizer
import requests
from bs4 import BeautifulSoup
import matplotlib.pyplot as plt
from wordcloud import WordCloud
from collections import Counter
from matplotlib.font_manager import FontProperties
import re
# 日本語フォントを設定
jp_font_path = '/usr/share/fonts/opentype/noto/NotoSansCJK-Regular.ttc'
jp_font = FontProperties(fname=jp_font_path)
# ウェブページを取得
url = 'https://joho-terakoya.com/'
response = requests.get(url)
response.encoding = response.apparent_encoding # 自動的に適切なエンコーディングを設定
soup = BeautifulSoup(response.text, 'html.parser')
# ページ内のテキストを抽出
text = soup.get_text()
# Janomeを使って形態素解析を行い、単語に分割
tokenizer = Tokenizer()
tokens = tokenizer.tokenize(text)
# 2文字以上で、数字を含まない名詞だけを抽出
words = [token.surface for token in tokens if token.part_of_speech.startswith('名詞') and len(token.surface) > 1 and not re.search(r'\d', token.surface)]
# 単語の出現頻度をカウント
word_counts = Counter(words)
# 最も頻出する単語を上位20件取得
most_common_words = word_counts.most_common(20)
# 出現頻度の高い単語を棒グラフで表示
words, counts = zip(*most_common_words)
plt.figure(figsize=(10, 8))
plt.barh(words, counts)
plt.title('Top 20 Most Common Words in https://joho-terakoya.com/)', fontproperties=jp_font)
plt.xlabel('Frequency', fontproperties=jp_font)
plt.ylabel('Words', fontproperties=jp_font)
plt.xticks(fontproperties=jp_font)
plt.yticks(fontproperties=jp_font)
plt.gca().invert_yaxis() # 順位が上の単語が上に来るように反転
plt.show()
# ワードクラウドで上位500単語を表示
most_common_words_500 = word_counts.most_common(500)
words_500 = [word for word, count in most_common_words_500]
wordcloud = WordCloud(font_path=jp_font_path,
width=1200, height=600, background_color='white',
max_words=500).generate(' '.join(words_500))
plt.figure(figsize=(15, 8))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.show()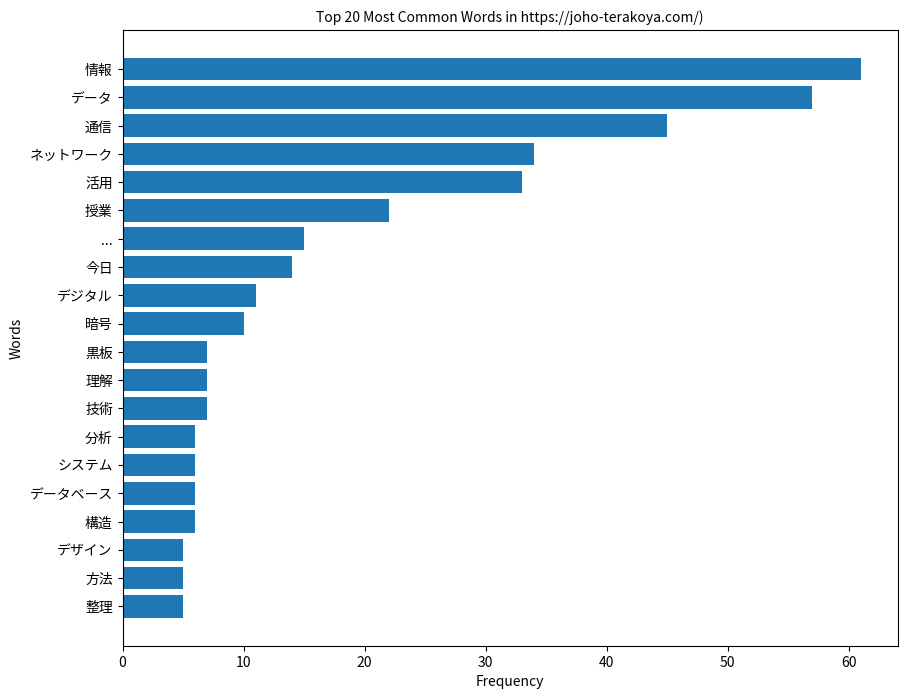
早速実行。何か棒グラフが出てきたよ。単語の出現順だね。
そうだよ。最もよく使われる20の単語を棒グラフで見ると、どんなキーワードが重要かがわかるよ。
情報という言葉は何度使ったかわからないね。感無量!
ワードクラウドの魅力

棒グラフの下にある、ぐちゃぐちゃした文字の集まりは何ですか?
これはワードクラウド(Word Cloud)という表現だよ。
ワードクラウド?雲みたいな感じですか?
うん、文字が雲のように集まったイメージだね。頻出する単語が大きく表示されるから、一目でどんな単語が重要かわかるんだ。
面白い表現だね。もしかして、プログラムを少し変えれば他のサイトの文章も解析できるね。
その通り、このPythonプログラムで、20行目のurl = のあとを他のサイトに変えてみて。
よし、じゃあこのサイトに書き換えて、実行してみるよ。さあ、この結果は何の解析だと思う?

「メロス」、「暴君」・・・。これは「走れメロス」だね。ちょっと簡単すぎじゃない?
たしかに、ひねりがなさ過ぎました・・。次の青空文庫のURLを分析してみました。https://www.aozora.gr.jp/cards/000035/files/1567_14913.html
音声認識と形態素解析の関係
ところでなおや君、音声アシスタントって使っているかな?例えばSiriとかAlexaとか?
もちろん!めっちゃ使っています。あれって音声を認識する技術ですよね?
実はそれだけじゃないんだ。音声認識は、音声をテキストに変換するだけど、その後に重要なのが自然言語処理なんだよ。
自然言語処理?これまで学んだ形態素解析とは別の技術?
実は、自然言語処理には形態素解析が大きく関わっているんだ。形態素解析を使って、音声から変換されたテキストを言葉の最小単位に分解するんだよ。
なるほど、そこで形態素解析が使われるんですね!
そうだね。さらに、構文解析で単語同士の関係を理解し、文脈解析で文全体の意味を把握する。これらのプロセスがあるからこそ、SiriやAlexaが賢く応答できるんだよ。
ただ音を聞くだけじゃなくて、言葉の意味まで考えてくれているんですね。すごいなぁ!
その通り。そして、この技術は日々進化していて、どんどん賢くなっているんだ。ChatGPTなどの生成系AIも、まず文章を言葉の単位に分けてから学習しているんだ。ここで形態素解析が使われている。
へー、AIが賢くなるためにはなくてはならない技術なんですね。今度はAIについても詳しく勉強していきたいです。よろしくお願いします!
まとめ
- テキストマイニングの概要
テキストマイニングは、文章データを解析し、有用な情報を抽出する技術である。 - 形態素解析の重要性
形態素解析を用いて、文章を言語の最小単位で分解し、データを整理・分析する。 - 視覚化の手法
得られたデータを棒グラフやワードクラウドなどで視覚化し、分析結果をわかりやすくする。 - AIと音声認識との関係
AIや音声認識も形態素解析を活用しており、テキストマイニングと密接に関連している。 - テキストマイニングの効果
テキストマイニングは、データの客観的な分析を可能にし、提供側の状態把握に役立つ。
名言解説
“The study of language is the study of the mind.” – Noam Chomsky
ノーム・チョムスキーは、現代言語学の父とも呼ばれる世界的に有名な学者です。彼は、人間の言語能力を探求し、その背後にある脳のメカニズムを解明することに尽力してきました。彼の理論は、言語を単なるコミュニケーションの手段としてだけでなく、人間の思考や認知の核心に迫るものと位置づけています。
この名言「言語の研究は、心の研究である。」は、言語を通じて私たちの思考や知識、感情がどのように形成され、表現されるのかを理解することが、心の働きを知るために重要であることを示しています。チョムスキーは、言語が単なる言葉のやり取り以上のものであり、私たちが世界をどう理解し、どう考えるかを反映していると考えました。
高校生の皆さん、テキストマイニングは、言語のデータを分析して意味やパターンを抽出する技術です。これを学ぶことで、膨大なテキストから価値ある情報を見つけ出す力を身につけることができます。それは、まさに心の一部を理解するための探求とも言えるでしょう。チョムスキーの言葉を胸に、言語を通じて自分の思考を深め、データの中から新しい洞察を得る力を育んでください。それは皆さんの未来に向けた重要な一歩となるはずです。
問題
「クイズをスタート」のボタンをクリックすると、5問出題します。さあチャレンジ!
編集者ひとこと
テキストマイニングいかがでしたか。
前々から、情報寺子屋ブログをマイニングしてみたいと思っていたので、ちょうどよい題材になりました。また、文学作品のテキストマイニングも面白いですね。走れメロスのほかにも、いくつかの作品を分析してみましたが、ワードクラウドを見るだけでストーリーを思い出してしまうものもあり、ちょっとはまりそうです。
さて、この「テキストマイニング」で教科書に沿った授業は最後です。ただし、これからもアップデートを続けますのでお楽しみに。
<RANKING>![]()
高校教育ランキング

